Selenium이라고 하면 테스트 자동화에 사용하는 것보다 크롤링을 떠올리게 됩니다.
수 많은 데이터들을 가져와서 내가 필요한대로 가공하기도 하고, 심지어 서비스를 제공하는 곳도 있습니다.
이번에는 가장 기초중에 하나인 네이버 영화 리뷰 타이틀을 크롤링 하는 법을 구현해보려고 합니다.

사전조건
: Pycharm, Python 3.X , 라이브러리 ( beautifulsoup, requests, lxml ) 설치 필요
1.네이버의 영화에 들어가서 영화 선택을 합니다.
네이버 영화
영화에 대한 모든 것
movie.naver.com
2. 저는 '엔트맨과 와스프: 퀀텀매니아' 영화 리뷰를 가져오기 위해 영화 검색을 한 후 [리뷰] 탭을 클릭했습니다.
주소 : https://movie.naver.com/movie/bi/mi/review.naver?code=193855

3. 아래와 같이 requests, BeautifulSoup 패키지를 설치했습니다. (주석을 통해 설명 생략)

4. 브라우저에서 F12를 누르고 리뷰 내용을 클릭하면 빨간색 네모박스와 같이 리뷰에 대한 html 구조가 나옵니다.
<ul class="rvw_list_area"> 아래로 2개의 <li> 가 보입니다. 리뷰가 총 2개 있다는 뜻입니다.
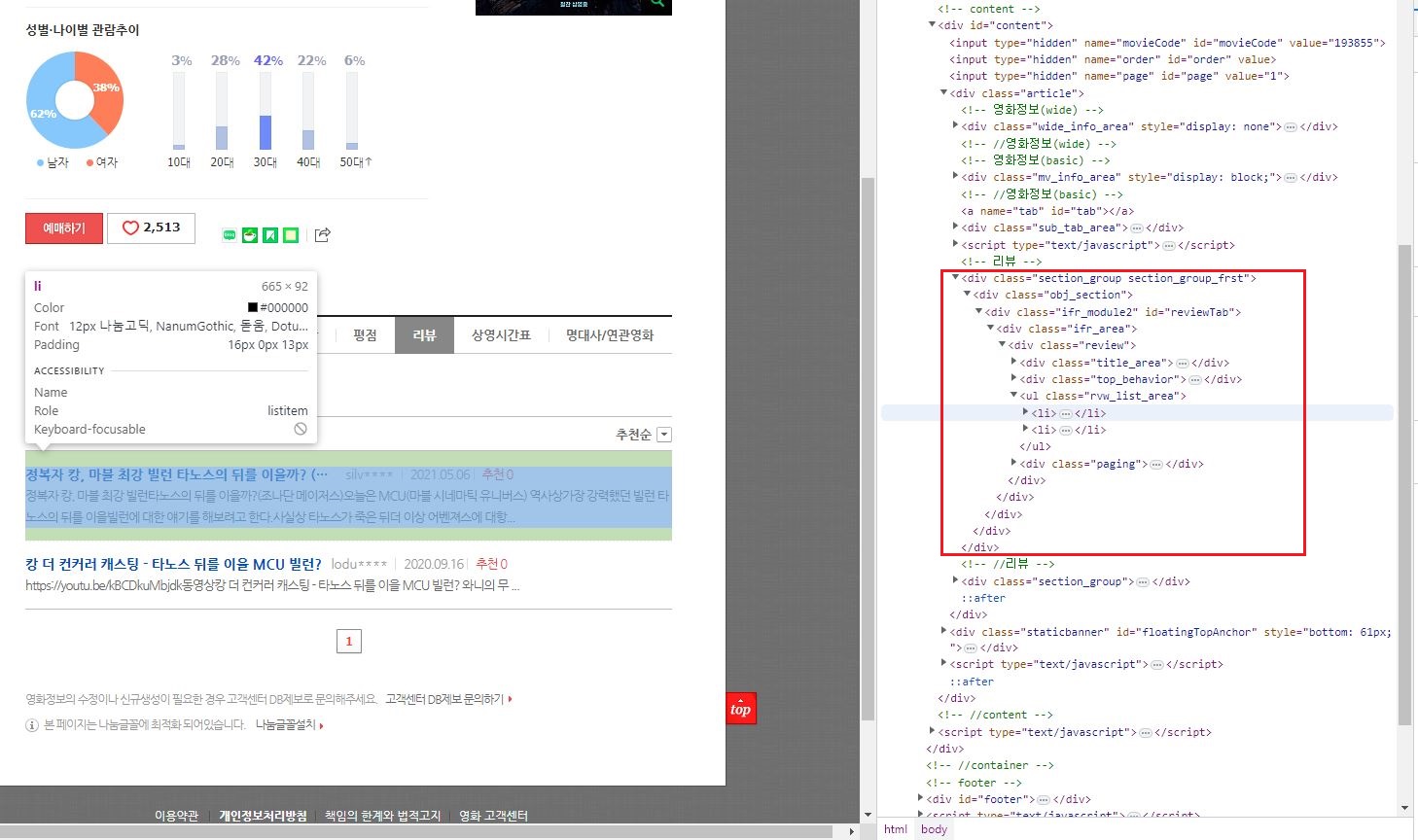
5. <li> 갯수만큼 for문을 돌리면서 <a> 태그 아래 <strong> 의 리뷰 내용을 가져오면 됩니다.

6. 아래와 같이 html 소스를 파싱하여 원하는 정보를 얻어올 수 있습니다.
<ul>
ㄴ<li>
ㄴ<a>
ㄴ <string>
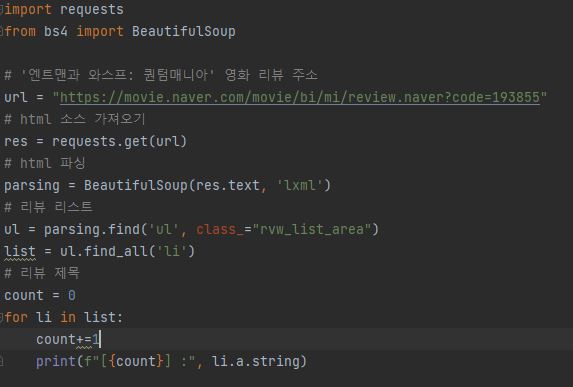
수행 결과 :

이렇게 해서 간단하게 영화 리뷰 제목을 크롤링 해봤습니다.
크롤링을 하여 구현할 수 있는 것이 어마어마하게 많은데 차차 재밌는 것들을 업데이트 해보겠습니다.
'프로그래밍 > python' 카테고리의 다른 글
| 법정동 코드는 어디서 확인할까? (0) | 2023.02.27 |
|---|---|
| 국토교통부 API로 아파트 매매 실거래가 구하기 (0) | 2023.02.26 |
| Mac에서 Python 기본 버전 변경하는 방법 (0) | 2022.03.16 |